CS
[OS] 세그멘테이션 Segmentation
D0HAN.
2021. 6. 27. 21:42
페이징 : 프로세스를 정확하게 일정한 간격(페이지)으로 잘라 메모리에 적재하는 방법
세그멘테이션 : 프로세스를 논리적 단위(세그먼트)로 잘라서 메모리에 적재하는 방법
✔️세그멘테이션
- 페이징과 같이 가상 메모리를 관리하는 기법 중 하나.
- 세그멘테이션에서는 프로세스= 세그먼트의 집합
- 프로세스를 논리적 내용을 기반으로 나눠 메모리에 배치. => 각 세그먼트는 연관된 기능을 수행하는 하나의 모듈 프로그램
- 한 프로세스는 기본적으로 세가지 segment로 나눌 수 있음 (그 안에서 각각 더 작은 세그먼트로 나눌수도 OO)
- Text(=code) segment(Read) - 프로그램의 기계어 명령이 들어있음
- Data segment(Read & write) - 초기화 된 전역변수, 정적 변수 저장
- Stack segment & Heap segment - 크기가 가변적. - 보호와 공유 용이
- 보호 : 테이블에 r,w,x 비트를 테이블에 추가. 논리적으로 나눠진 세그먼트별로 해당 비트를 설정하기 때문에 간단하고 안전함. paging은 크기로 나누기 때문에 영역이 섞일 수 있어 비트를 설정할 때 까다롭다.
- 공유 : 필요한 부분이 연관된 기능을 수행하는 세그먼트로 나눠지기 때문에 효율적인 공유 가능
✔️세그먼트를 메모리에 할당하는 법
- 페이징과 같음
- *MMU내의 재배치 레지스터를 이용하여 논리주소 -> 물리 주소로 바꿈.
* MMU(Memory Management Unit): CPU가 물리적 메모리에 접근하는 것을관리하는 하드웨어 장치.
MMU는 세그먼트 테이블로 CPU에서 할당한 논리주소에 해당하는 물리주소의 위치를 가지고 있음
MMU의 STBR(Segment Table Base Register)에 segment table 시작주소 넣어줘서 접근 가능하게 함.
- 세그먼트 테이블은 physical 메모리의 unmap된 영역에 저장됨.
- 세그먼트 테이블: 세그먼트 번호, 시작 주소(base), 세그먼트 크기(limit)을 엔트리로 가짐
✔️논리-물리 주소 변환 법
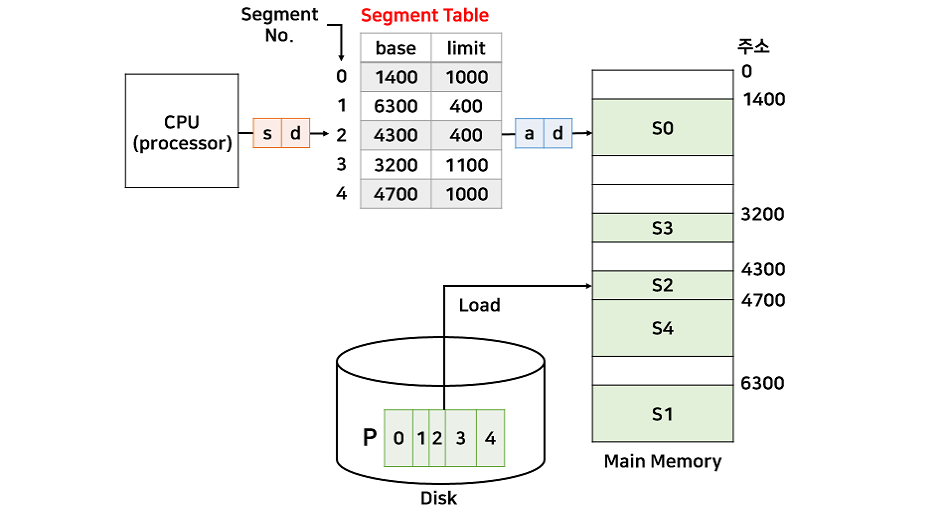

- 페이징과 비슷, 테이블이 다름(페이징은 페이지 테이블 사용)
- 논리주소는 v = (s,d) 로 표현됨
- 논리주소 = s 세그먼트 번호(테이블의 인덱스로 사용) + d 오프셋(길이랑 비교)
물리주소 = a 세그먼트 테이블에서 base (시작 물리 주소) + d 오프셋 - ex. 논리주소 (2,100) = 물리주소 4400
논리주소 (1,500) = 인터럽트로 인해 프로세스 강제 종료(limit 벗어남) - 리눅스에서 자주 볼 수 있는 오류인 segmetation fault 도 권한,범위 밖의 메모리를 참조하려 할 때 일어남.
- 논리주소에서 보내는 주소값에서 하위 변위비트(오프셋,d) 빼고, 앞의 비트들은 세그먼트 번호(세그먼트 테이블 인덱스로 사용)
✔️장점
- 보호와 공유 면에서 효과적
- 두 user process가 동일한 코드(text segment)를 공유하기 용이.
- 각 memory section 들에게 각기 다른 read/write권한 설정할수있음
- 내부단편화 발생하지 않음
✔️단점
- 세그먼트는 크기고정 x, 가변적이라 동적 메모리 할당을 해야함. -> 외부단편화가 발생할수있다
=> 너무 큰 단점이라 segmentation 거의 사용하지 않음 - 평균 세그먼트 크기가 작을수록 외부 단편화 작음

보완
- 세그먼트를 페이징. -> 세그먼트 안에 별도의 페이지 테이블 존재
- 논리 주소 = 세그먼트 번호/페이지 번호/오프셋
- 외부 단편화 적음.
- but 테이블 두개를 거쳐야 해서 속도 느림(각 사용자의 메모리 3번참조)
CPU -> 세그먼트 테이블 -> 페이지 테이블
오버헤드가 커짐 - Multics, 인텔 386계열에서 사용